

Dev Diary #1


Table of contents
A few weeks ago I decided to drop C# and focus on java.
In the last few weeks, I rewrote the Encyclopedia Galactica project to java and I'll do a walkthrough now.
The whole project was built in Spring. I'm trying to apply some of the Domain Driven Design principles I'm aware of. The fact is that I know little about it and I know that clean code and clean architecture come with it. I apply these principles slowly at the pace I see fit.
Architecture
The application is a 3-tier architecture. The database is planned to be Postgres, the business logic layer is Spring and the UI is HTML and it seems HTMX. If I take a look at the whole domain I want to be covered by this app the architecture will be event stream with microservices and all the nine-yard. For more details see the project's page.
Since I develop this beast alone I have to keep it as simple as possible.
Codebase
At this level I try to apply clean code and clean architecture things. As I mentioned previously I'm not experienced in this yet. But, if I were I would not apply them blindly. Whatever I do it has to go through my understanding.
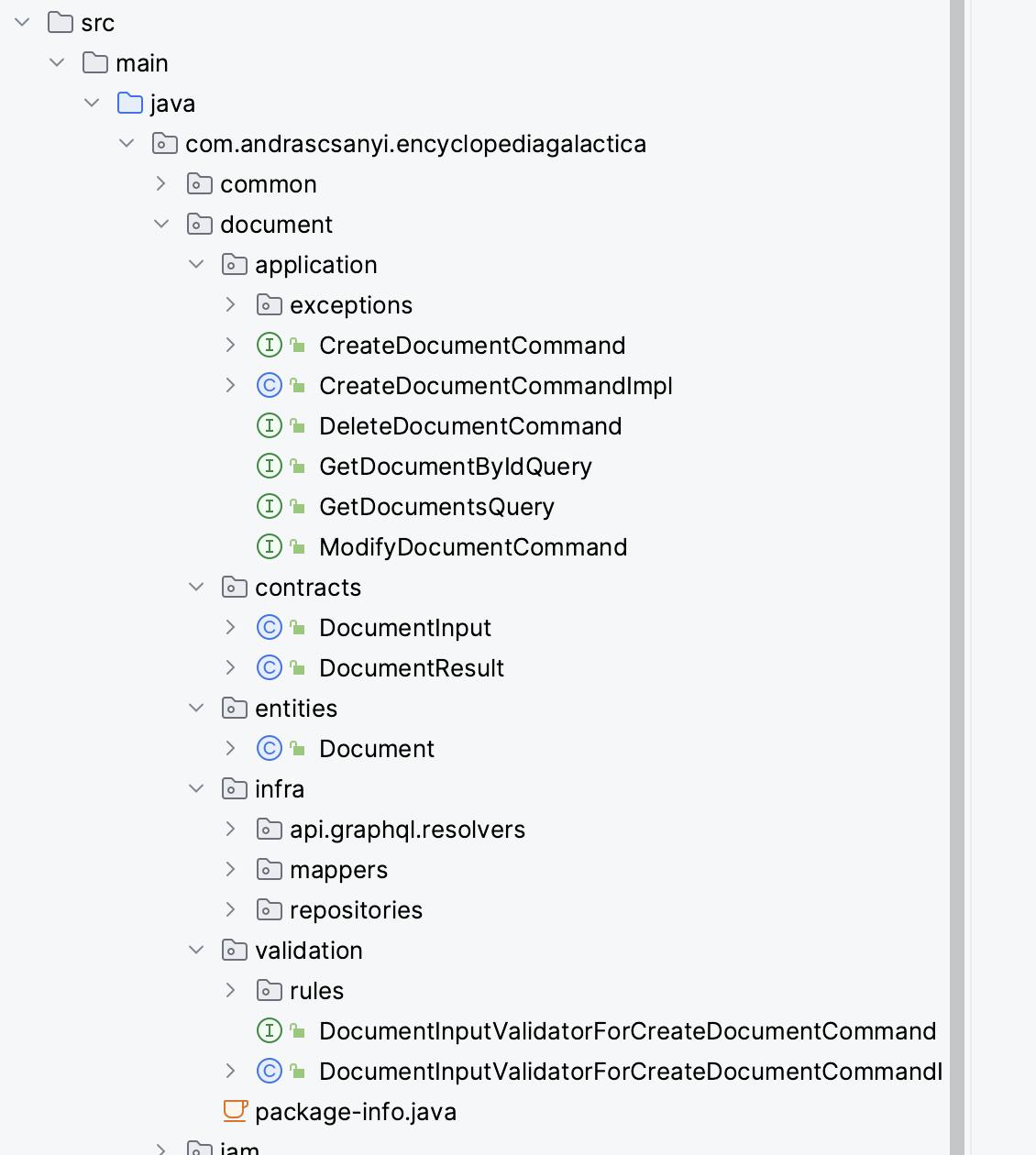
We have 4 modules. The common (1) is the cross-cutting concerns. The document (2)and iam (3) modules are the business domains, and the ui (4) is the user interface.

The application directory contains the business functionalities of a single module. There are commands and querys, but highly probable that I'm going to rename these to scenario. The reason is that I've got used to BDD language and there, everything is a scenario. My brain works better when it comes to scenarios and there is no brain froze when a command includes a query or vice versa. A scenario is a forgiving definition from this point of view.
When it comes to contracts I don't use a single DTO for input and output. I rather separate them. Why? Because... why not? I feel that this level of separation is good.
entities are the domain objects. These are persisted in the database and all the domain related operation happens to them.
infra includes Graphql and Rest endpoints related things, the mappers and the repositories. The infra stuff for Graphql means the controllers including the @QueryMapping and @SchemaMapping bindings to the application logic.
mappers directory includes the mappers implemented by MapStruct. Even though I like to write the mappers by hand and test the hell out of them I found MapStruct to be a good tool. The mapper code is generated by Maven, I only have to define the interface. This looks good so far.
repository is where I leverage on Spring's Data JPA magic. These are just interfaces without any code written by me. There will be a point where I have to write repository-level logic and those files will be placed here.
validation contains the validation for the business scenarios. I create one or multiple validators for each business scenario. I use Hibernate Bean Validator for this.
The testing part of the codebase looks like the following. Every domain (document, iam) have its directory, and within one there are tests for infra and validation, and there is specification for E2E tests.
Even though MapStruct is a well-tested library I still test what the mapper is doing. Unnecessary, but I still want to see everything is going well.
I still haven't decided how to test the repositories. These are interfaces and Spring does its magic to provide implementation. The logic I applied to MapStruct should be applied here too. I don't feel it right. I haven't decided if I want to provide tests against every repository method or not.
The pro for repository testing is my plan to ditch Spring generated repositories and rather I will provide implementations. I see value in this in terms of I have to practice working with Hibernate ORM. Tests, in this case, provide what they always should: you can refactor the code safely.
The specification directory shows how the endpoints (GraphQL and Rest) and the application itself should behave from a consumer point of view.
The validation directory includes the validator tests. Since, I write the validation rules I need to test if I reached the expected behaviour or not.

Devops
The project was built by maven.
The CI build is running on Github.
Versioning is done by semantic-release but not by its Github Actions, I use rather a script version.